
中国电子元件行业协会
China Electronic Components Association



声学检测与识别在医疗监护、环境感知及人机交互(HRI)等领域至关重要,但传统声学传感器因体积大、灵敏度低、动态范围有限和缺乏柔性,难以集成到新一代可穿戴设备中。现有柔性传感器在弯曲时性能显著下降,严重制约其在动态环境中的应用。
清华大学王晓浩研究员、董瑛副研究员团队开发出一种压电驻极体薄膜声学传感器(PETAS),通过创新性结构设计解决了上述难题。该传感器由振动膜、间隔层和氟化乙烯丙烯(FEP)驻极体层组成,利用电晕极化使气隙充分带电,通过解耦振动膜与驻极体层显著提升带宽与灵敏度。实验表明,PETAS在0–830 Hz频段输出稳定,灵敏度达2.744 pC/Pa(500 Hz),耐久性超10万次工作循环和1000次弯曲循环,人机交互指令识别准确率超96%,抗环境噪声能力远超商用麦克风。
核心设计与工作机制
PETAS采用多层堆叠结构(图1):8 μm厚聚酰亚胺(Kapton)振动膜覆盖铬/铜电极,50 μm聚对苯二甲酸乙二醇酯(PET)间隔层防止高压塌陷,双层FEP驻极体通过激光切割形成交叉沟槽阵列,热压封装后实现15/16孔隙率(图1c)。气隙壁捕获电荷形成电偶极子,声压引发振动膜与驻极体层间距变化,破坏电场平衡并驱动电荷重新分布,产生压电响应(图1d-e)。仿真优化显示,15 mm边长振动膜可平衡灵敏度与带宽,一阶谐振频率1001 Hz覆盖生理声信号频段(图1f-h)。

图1 压电驻极体薄膜声学传感器(PETAS)整体设计 a) PETAS应用于人机交互的场景示意图。 b) PETAS结构示意图。 c) (i) 双层FEP薄膜顶视图;(ii) 图(i)虚线框区域放大图;(iii) 截面SEM显微图(A-A平面),显示精密沟槽封装形成的气隙通道。比例尺:500 μm。 d) 含双层FEP储电膜与Kapton振动膜的组件截面图。 e) PETAS工作原理示意图。 f) PETAS中Kapton振动膜的一阶(1001 Hz)和二阶(2051 Hz)振动模态仿真结果。 g) 一阶谐振频率随振动膜边长变化呈平方反比趋势。 h) 表面最大位移随振动膜边长呈四次方趋势。
制备工艺与器件特性
制备流程(图2a)包括激光刻蚀FEP沟槽、正交堆叠热压、铜电极贴合、声学孔加工及电晕极化(-20 kV/8分钟)。成品厚度仅146 μm,重量0.32 g(图2b),可贴合高曲率表面(半径30 mm)及人体皮肤。性能测试(图3)证实其频响覆盖0–830 Hz(94 dB声压),灵敏度线性范围达20 Pa,信噪比超48 dB,动态范围70–120 dB。经1000次弯曲循环(图3g)及不同曲率测试(图3h),电荷输出保持稳定,方向性呈"8"字形分布。
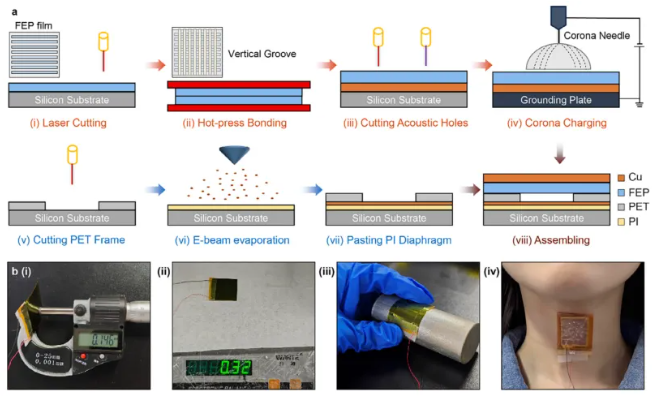
图2 PETAS制备流程与特性 a) 激光切割与多层组装工艺示意图。 b) PETAS实物图:(i) 总厚度146 μm;(ii) 总重0.32 g;(iii) 贴合高曲率表面;(iv) 贴合人体皮肤。
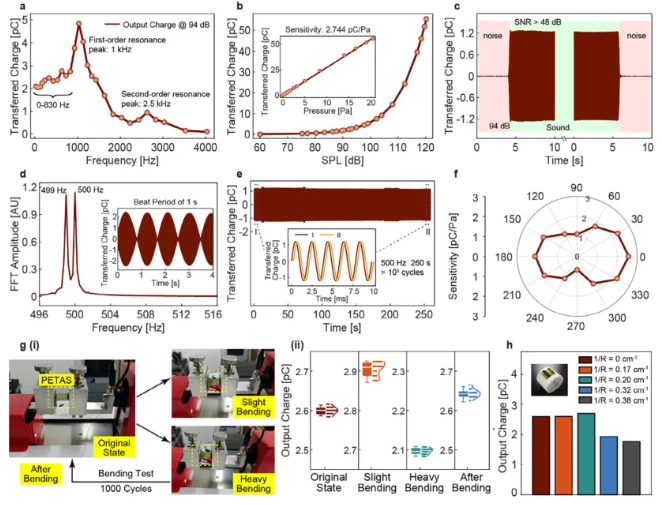
图3 PETAS性能表征 a) 94 dB声压级(1 Pa)下电荷传输的频率响应曲线。 b) 500 Hz输入时不同声压级下的电荷变化,插图为20 Pa内线性响应及2.744 pC/Pa灵敏度。 c) 500 Hz/94 dB输入下的等效噪声测试,信噪比超48 dB。 d) 频率分辨率测试:1 Hz差异混合声的时/频域电荷响应。 e) 260秒(>10⁵周期)连续声压下的电荷输出稳定性,插图为始末阶段波形对比。 f) 方向性测试结果。 g) 柔性性能测试:(i) 弯曲循环流程;(ii) 1000次弯曲中四种状态的电荷输出。 h) 不同曲率下的电荷输出。
多源声学信号检测
PETAS在钢琴音阶检测中频率相对误差低于0.1%(表1),精准分离复合音(图4a-c);录制英文" sensor"及中文"传感器"时,输出电压比商用麦克风高近一个量级,谐波成分更清晰(图4d)。志愿者元音测试(图4e)显示其可提取基频(F0)、抖动度等语音健康参数(表2)。此外,成功捕捉人体拍手声(图4f-i)、心音S1/S2成分(图4f-iii)及狗吠等复杂声源。
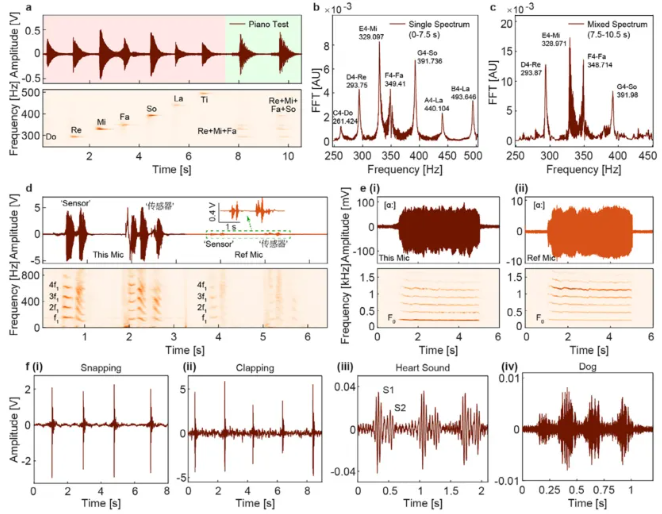
图4 多声源测量与分析 a) 钢琴单音/复合音对应的时间序列(上)与短时傅里叶变换(STFT)谱图(下)。 b) 图a中0–7.5秒段的FFT结果。 c) 图a中7.5–10.5秒段的FFT结果。 d) PETAS与参考麦克风对中英文"传感器"的响应对比:时间序列(上)及STFT谱图(下)。 e) 志愿者发元音/a:/时PETAS与参考麦克风响应对比,展示语音健康评估潜力。 f) 其他应用场景:(i) 人体弹指声;(ii) 拍手声;(iii) 心音信号;(iv) 狗吠声。
噪声环境下的语音识别
基于梅尔频率倒谱系数(MFCC)模板匹配算法(图5a),PETAS在96.5 dB高噪声下仍保持92%指令识别率(图5c)。不同弯曲半径(30–80 mm)、中英文指令及志愿者差异测试中,识别准确率均超96%(图5d)。空间定位测试(图5e)表明,在10–20 cm距离与±30°角度范围内,各曲率下识别率超90%。

图5 不同测试条件下的语音识别准确率 a) 基于MFCC特征提取的PETAS人机交互系统框架。 b) 八种指令的混淆矩阵。 c) 背景噪声对识别率的影响。 d) 三位志愿者的中英文指令在不同弯曲半径下的识别率。 e) 不同曲率下说话角度/距离对识别率的影响。
人机交互验证
颈戴式PETAS在家庭陪护(安静环境)和工业机器人(噪声环境)场景中均表现卓越(图6)。工业场景中,其输出指令信号纯净,而商用麦克风受环境噪声严重干扰(图6d),凸显其抗噪优势。该技术有望推动语音安防、无人机控制及AI通信等领域发展。

图6 颈戴式PETAS人机交互实验 a) 实验流程示意图。 b) 机器人两种工作环境设计。 c) 安静环境下的指令与机械手响应。 d) 噪声干扰下的指令与机械臂动作。
总结与展望
PETAS以解耦设计和微结构优化实现高柔性、高灵敏度与强噪声免疫,为人机交互系统提供可靠平台。未来研究将聚焦热稳定性提升(超100℃)、FEP孔隙率优化及高频超声检测(5–50 kHz)拓展,进一步释放其在可穿戴电子与先进HRI系统中的潜力。